Humans have the remarkable ability to understand 3-D objects just from looking at one angle. We can imagine the shape of a deer from a quick glimpse on a highway, understand that a wall continues beyond the furniture around it, and perceive a full sofa that we’ve only seen peripherally, all of which helps us navigate the complex world we live in.
Computers don’t have this innate ability to understand things like perspective, symmetry, and physics -- they need to be taught it. Traditionally, machines are fed large data sets in the hopes of being able to classify specific objects, but then they can’t do much beyond that. For instance, if you train your system on chairs and test it on tables, you’d be out of luck.
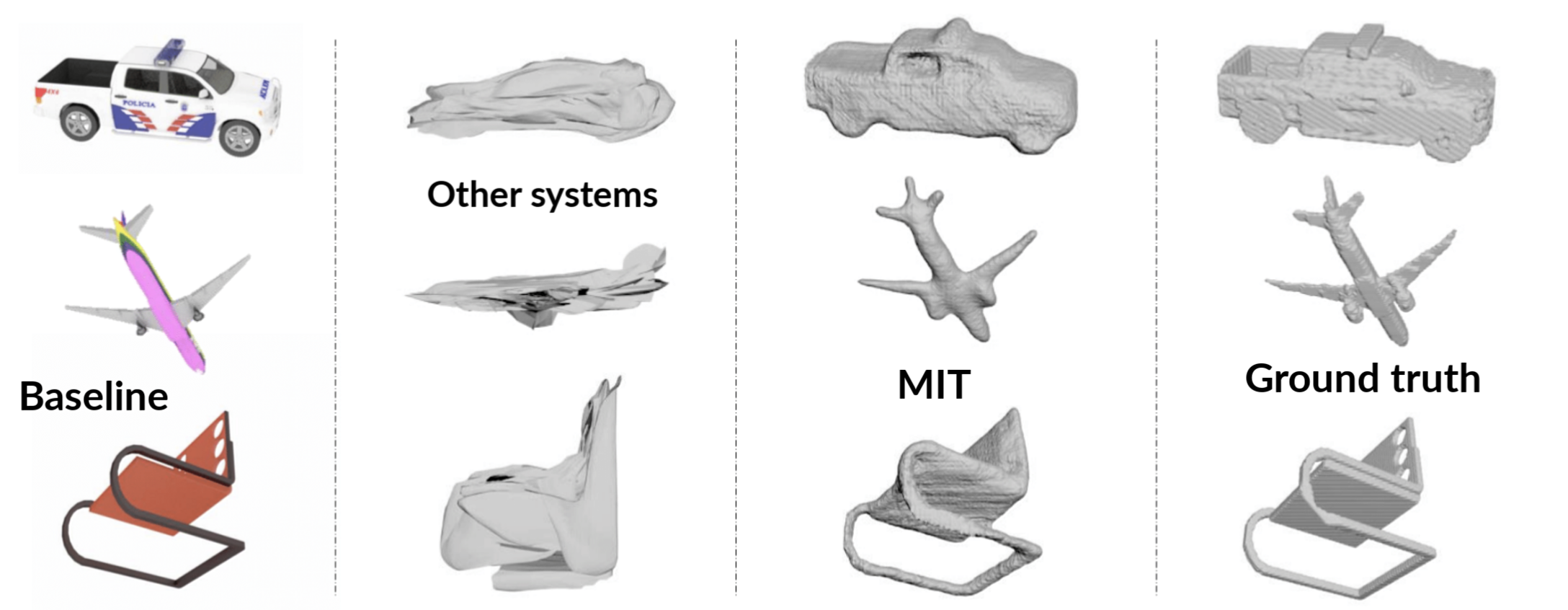
In a new paper out of MIT’s Computer Science and Artificial Intelligence Laboratory (CSAIL), a team has come up with a way for machines to perceive objects more like humans, by developing an algorithm that can create full 3-D shapes from single 2-D images.
You can imagine one day being able to use a system like this to help self-driving cars better navigate their surroundings, enable robots to decipher between objects, or to assist machines working in manufacturing settings.
In tests the team used their algorithm trained on cars, planes, and chairs to reconstruct a table from a single image, and it performed better than other systems that work only on the same classes used for training.
“Imagine a robot that can understand the difference between a bottle of medication and a glass of water in an assistive setting,” says Jiajun Wu, lead author on the paper. “Our ultimate goal is to make flexible models that can help humans in settings with significant uncertainty.”
How it works
Perceiving a full 3-D shape of an object from a 2-D image is a fundamentally ambiguous problem, because a 2-D image has "lost" the third dimension. To solve this, the team gathered information using a lesser known dimension, (no, not Platform 9 and ¾), but rather something called “2.5-D.”
Unlike 2-D, 2.5-D depictions of visual surfaces give us more information about depth and silhouettes. 2.5-D was originally coined by the late MIT professor David Marr, who viewed images in three stages.
First there’s a “primal sketch”, which outlines the general contours of the object. Then there’s the 2.5-D sketch, which provides more information about depth and surface than 2-D. And then finally, there’s the full, 3-D shape - a whole process similar to how humans perceive objects.
Bridging the gap between 2-D and 3-D, the system works by completing the non-visible parts of an unseen object from the 2.5-D sketches, using generic knowledge about symmetry and other aspects of shapes it has previously learned. This helps the algorithm to learn a general way of perceiving 3-D from 2-D that can be applied to new kinds of objects.
During tests, having seen only cars, chairs, and airplanes during training, the system could then reconstruct shapes of unseen objects, like sofas and even humans, from just single images.
Still, the system had difficulty with reconstructing objects from less representative viewpoints, where you’d need to reason about parts of the object you can't see at all in the image; imagine trying the reconstruct the front of an object while viewing it from the back. There were, unsurprisingly, fewer errors when more straightforward views of images were used. For example, a three-quarters view of a table would provide a more accurate sense of its full 3-D shape than a view of the table from the top, looking down, that excluded the legs.
In the future, the team hopes to improve the system to be able to capture more detailed nuances like texture. Currently, they only focus on shape, without any colors or specifics about the object that provides more details. The system learns based on rendered images of CGI objects, which is useful because it’s easy to evaluate since you know the true shape of the object. The real world, though, is much more complicated.
“Deep learning has had a huge impact in computer vision, and is very good at memorizing visual appearance from lots of data,” says Noah Snavely, an associate professor of computer science at Cornell University. “However, achieving more human-type capabilities like conceptualizing and abstraction -- understanding the world at a level that can be applied to new objects and situations -- is still a challenge. This work is meaningful step for computer vision because robots that interact with the world in a truly general way will need to react to things they have never seen before.”
Wu wrote the paper alongside CSAIL PhD students Xiuming Zhang, Zhoutong Zhang, and recent CSAIL MEng graduate Chengkai Zhang, and MIT professors Joshua B. Tenenbaum and William T. Freeman. The team just presented their work at the Neural Information Processing Systems (NeurIPS) conference in December.

