
Imagine that you’re in your kitchen, and you’re trying to explain to a friend where to return a coffee cup. If you tell them to “hang the mug on the hook by its handle,” they have to make that happen by doing a fairly extensive series of actions in a very precise order: noticing the mug on the table; visually locating the handle and recognizing that that’s how it should be picked up; grabbing it by its handle in a stable manner, using the right combination of fingers; visually locating the hook for hanging the mug; and finally, placing the cup on the hook.
If you think about it, it’s actually quite a lot of stuff - and we humans can do it all without a moment’s hesitation, in the space of a couple of seconds.
Meanwhile, for all the progress we’ve made with robots, they still barely have the skills of a two-year-old. Factory robots can pick up the same object over and over again, and some can even make some basic distinctions between objects, but they generally have trouble understanding a wide range of object shapes and sizes, or being able to move said objects into different poses or locations.
That may be poised to change: researchers from MIT’s Computer Science and Artificial Intelligence Laboratory (CSAIL) say that they’ve developed a new system that allows robots to do many different pick-and-place tasks, from hanging mugs to putting shoes on shelves, without having ever seen the objects they’re interacting with.
“Whenever you see a robot video on YouTube, you should watch carefully for what the robot is NOT doing,” says MIT professor Russ Tedrake, senior author on a new paper about the project. “Robots can pick almost anything up, but if it’s an object they haven’t seen before, they can’t actually put it down in any meaningful way.”
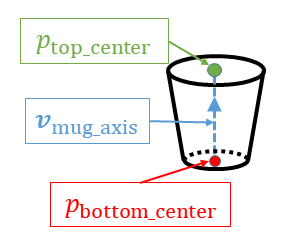
The team’s major insight was to look at objects as collections of 3D keypoints that double as a sort of “visual roadmap.” The researchers call their approach “KPAM” (for “Keypoint Affordance Manipulation), building on an earlier project that enabled robots to manipulate objects using keypoints.
The two most common approaches to picking up objects are “pose-based” systems that estimate an object’s position and orientation, and general grasping algorithms that are strongly geometry-based. These methods have major problems, though: pose estimators often don’t work with objects of significantly different shapes, while grasping approaches have no notion of pose and can’t place objects with much subtlety. (For example, they wouldn’t be able to put a group of shoes on a rack, all facing the same direction.)
In contrast, KPAM detects a collection of coordinates (“keypoints”) on an object. These coordinates provide all the information the robot needs to determine what to do with that object. As opposed to pose-based methods, keypoints can naturally handle variation among a particular type of object, like a mug or a shoe.
In the case of the mug, all the system needs are three keypoints, which consist of the center of the mug’s side, bottom and handle, respectively. For the shoe, KPAM needed just six keypoints to be able to pick up more than 20 different pairs of shoes ranging from slippers to boots.
“Understanding just a little bit more about the object -- the location of a few key points -- is enough to enable a wide range of useful manipulation tasks,” says Tedrake. “And this particular representation works magically well with today’s state-of-the-art machine learning perception and planning algorithms.”
KPAM’s versatility is shown by its ability to quickly incorporate new examples of object types. PhD student Lucas Manuelli says that the system initially couldn’t pick up high-heeled shoes, which the team realized was because there weren’t any examples in the original dataset. The issue was easily resolved once they added a few pairs to the neural network’s training data.
The team next hopes to get the system to be able to perform tasks with even greater generalizability, like unloading the dishwasher or wiping down the counters of a kitchen. Manuelli also said that KPAM’s human-understandable nature means that it can easily be incorporated into larger manipulation systems used in factories and other environments.
Manuelli was the co-lead author on the new paper with graduate student Wei Gao, alongside Tedrake and PhD student Pete Florence.
