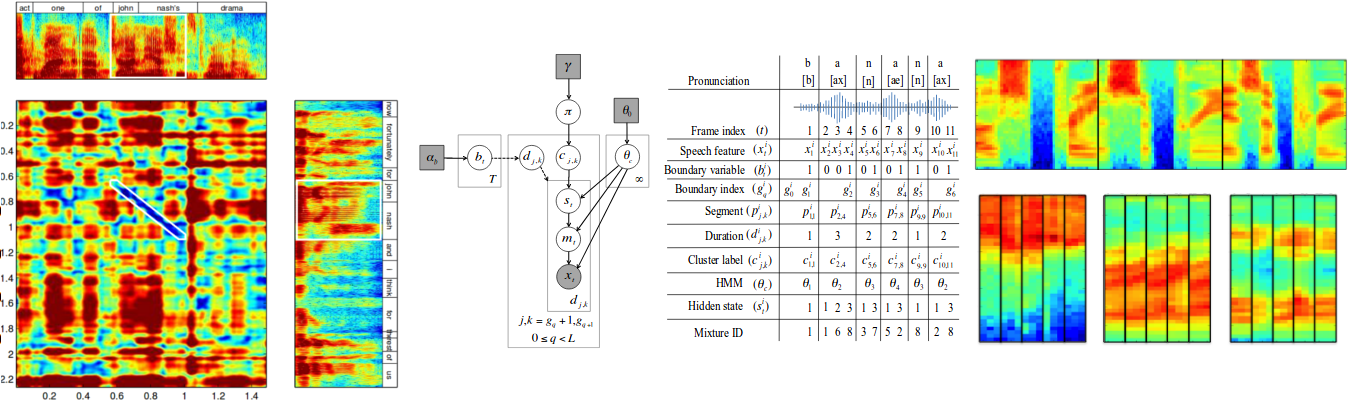
All humans process vast quantities of unannotated speech and manage to learn phonetic inventories, word boundaries, etc., and can use these abilities to acquire new word. Why can't ASR technology have similar capabilities? Our goal in this research project is to build speech technology using unannotated speech corpora.