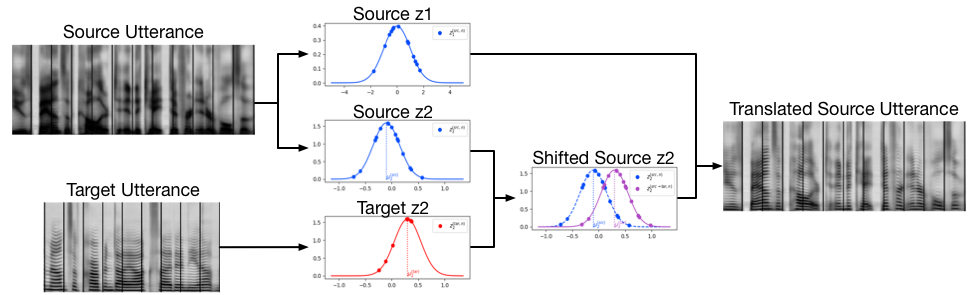
Generation of sequential data involves multiple factors operating at different temporal scales. Take natural speech for example, the speaker identity tends to be consistent within an utterance, while the phonetic content changes from frame to frame. By explicitly modeling such hierarchical generative process under a probabilistic framework, we proposed a model that learns to factorizes sequence-level factors and sub-sequence-level factors into different sets of representations without any supervision.