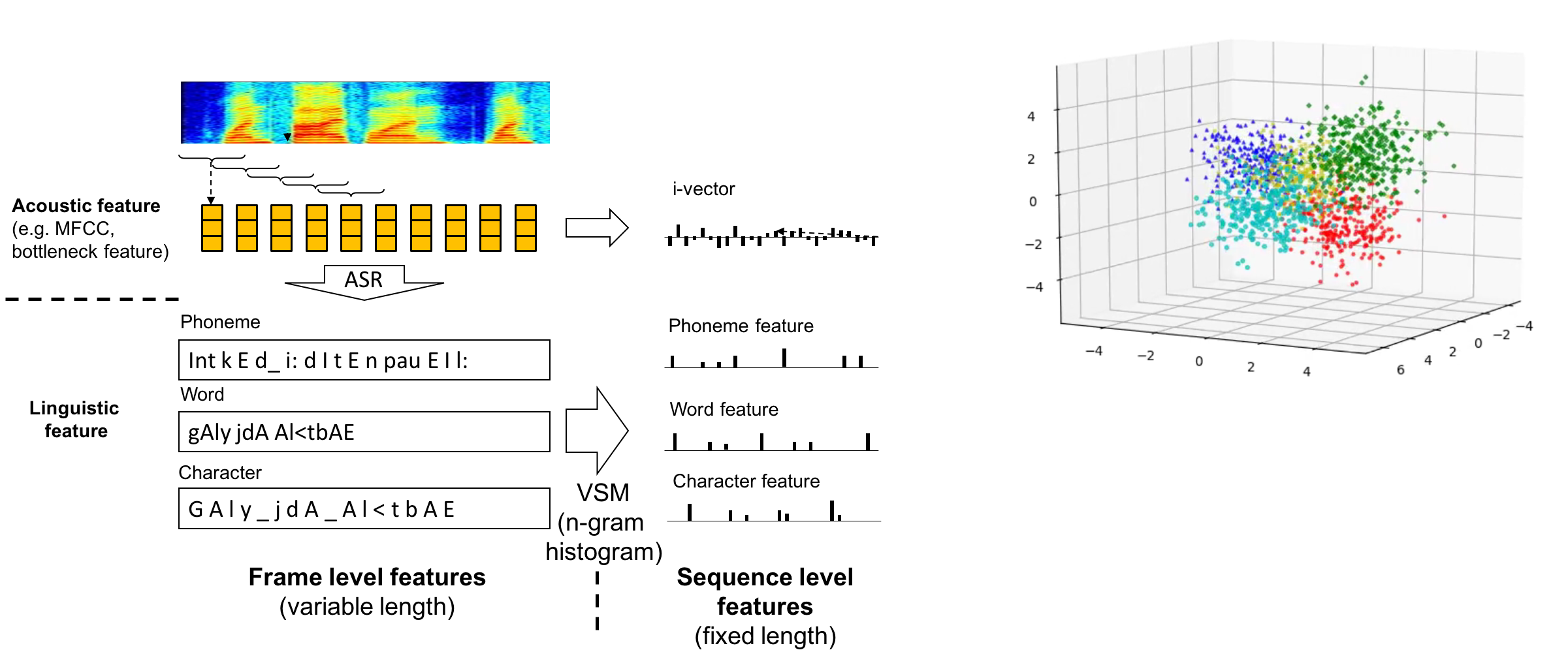
One of the challenges of processing real-world spoken content, such as automatic speech recognition, is the potential presence of different languages and dialects. Language and Dialect identification can be a useful capability to identify which language is being spoken during a recording.