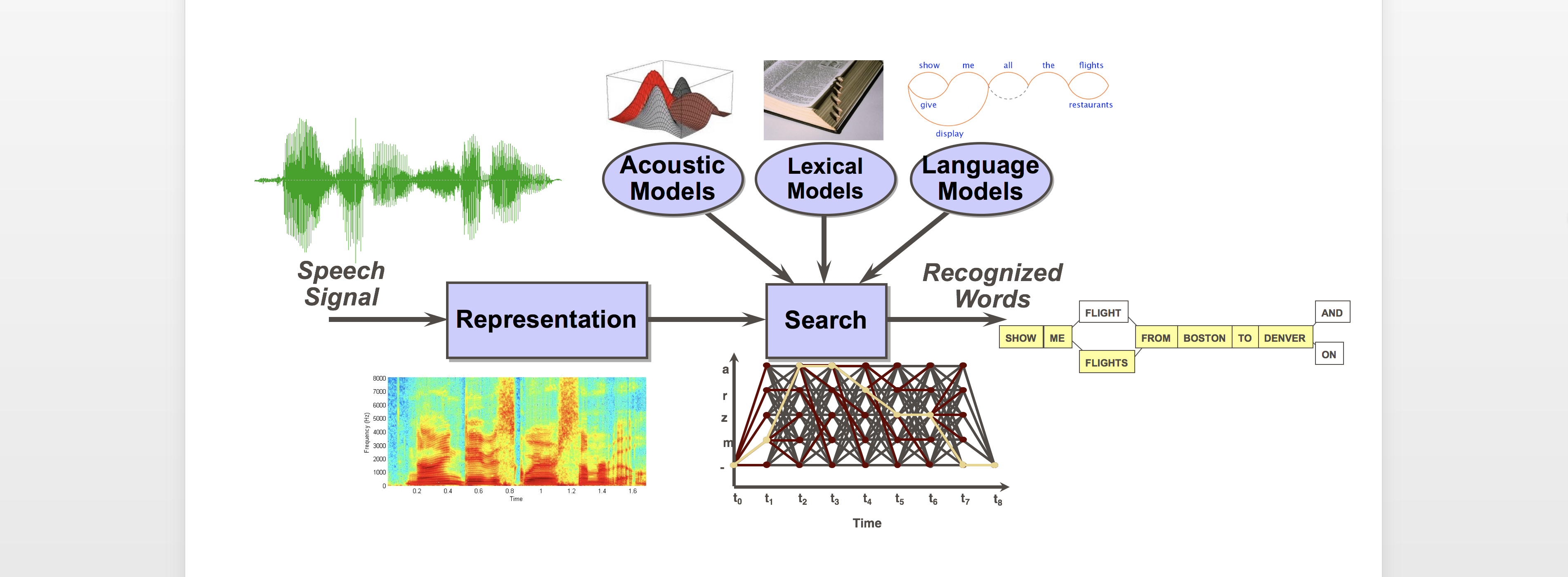
Automatic speech recognition (ASR) has been a grand challenge machine learning problem for decades. Our ongoing research in this area examines the use of deep learning models for distant and noisy recording conditions, multilingual, and low-resource scenarios.