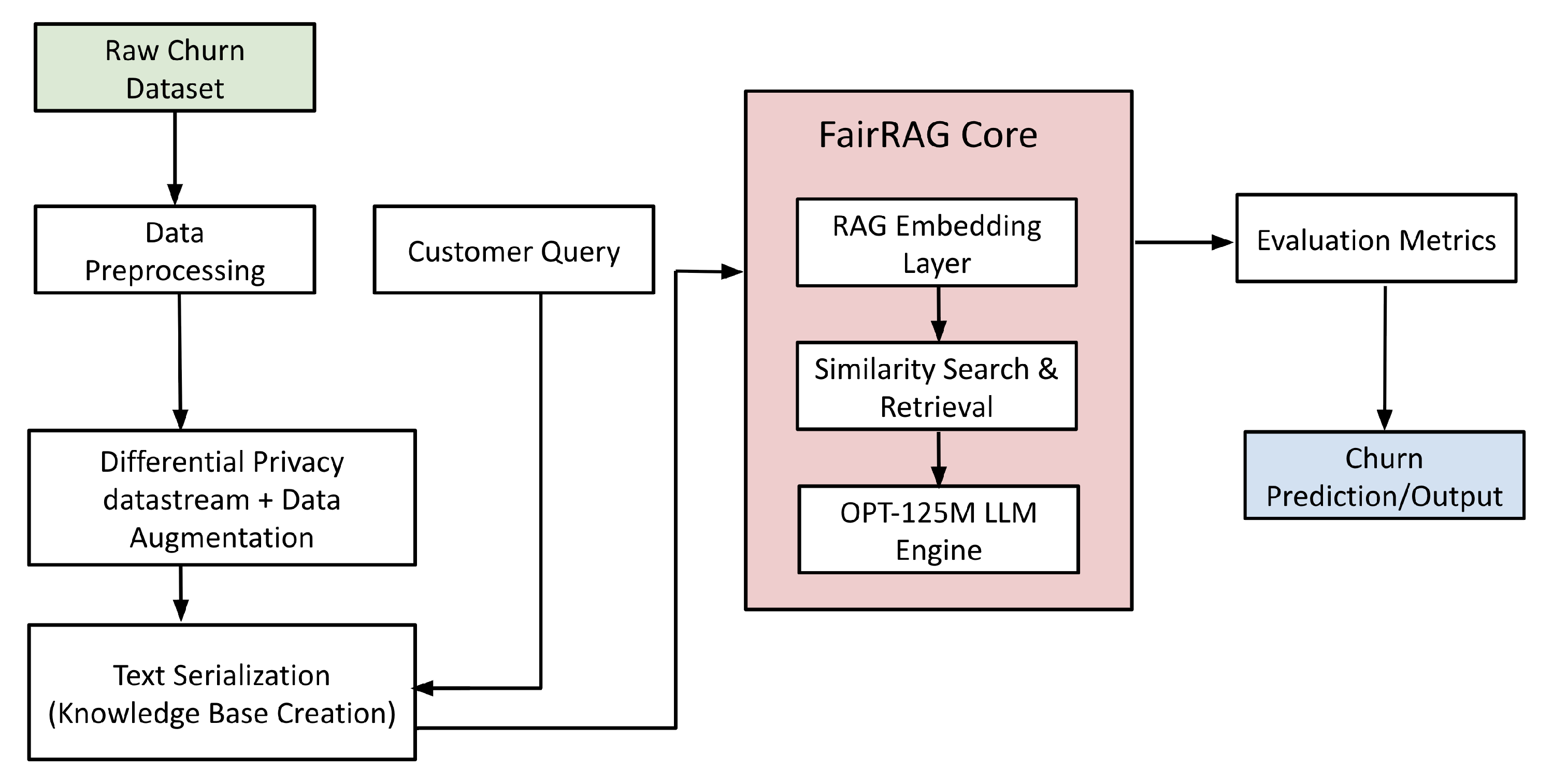
Customer data is a valuable asset for businesses, but its use presents a complex privacy challenge. Companies aim to predict customer churn, yet this process is increasingly restricted by privacy regulations such as GDPR and growing consumer concerns about data protection.
MIT researchers have built an architecture called "FairRAG" that utilizes differential privacy, retrieval-augmented generation, and large language models to predict customer churn while maintaining robust privacy protections. This work was led by MIT researcher and former professor Amar Gupta, visiting professor Rafael Palacios, research affiliate Rashmi Nagpal, and undergraduate student Unyimeabasi C. Usua.
A new approach to an old problem
“We realized that the customer churn prediction has long relied on classical machine learning models, which are trained directly on sensitive customer data. While they’re effective, these approaches raise privacy concerns and can perpetuate biases present in the training data”, adds Gupta. FairRAG addresses four challenges: providing higher accuracy than both classical machine learning models and off-the-shelf LLMs; bypassing the need for computationally intensive resources to fine-tune billion-parameter models; yielding a higher level of privacy guarantees; and having inherent interpretability. The researchers developed FairRAG by utilizing an open-source large language model released by Meta, specifically the OPT-125M model, and tested it on publicly available finance datasets, showing significant improvement in the fairness-accuracy tradeoff metrics.
FairRAG makes three distinct contributions. First, it serializes customer profiles into the retrieval knowledge base. Second, it decouples the privacy mechanism from the model training process. Third, it uses an open-source pretrained LLM, avoiding the high computational cost and complexity of the private fine-tuning process. "The existing research in customer churn prediction attempts to balance model performance with fairness and privacy guarantees, but faces challenges to address interpretability," says Palacios.
Beyond accuracy: Built-in interpretability
One of FairRAG's key advantages is its inherent interpretability. Unlike black-box models, the FairRAG framework provides clear explanations for its predictions by showing which similar customer profiles influenced each decision. This transparency is crucial for building a wide range of business applications, from financial risk assessment and healthcare diagnostics to customer service automation, where stakeholders need to understand AI-driven decisions. It helps them trust that the outcomes are reliable, fair, and aligned with regulatory and ethical standards. “FairRAG presents a significant step forward by providing a computationally efficient and privacy-preserving solution,” Nagpal adds.
The researchers acknowledge limitations that guide future work. The current evaluation focused on structured tabular data in the churn prediction domain, and broader validation across different domains is needed. “We plan to expand FairRAG's capabilities to handle multi-modal data and implement comprehensive fairness evaluation metrics,” adds Usua.
The team presented their framework as part of a paper being published this summer in the special issue of Applied Sciences, an MDPI journal. This research is funded, in part, by two industry alliances at the MIT Computer Science and Artificial Intelligence Laboratory (CSAIL): the Future of Data consortium and the FinTechAI consortium.


