Ben Recht: Optimization Challenges in Deep Learning
Speaker
Ben Recht
UC Berkeley
Host
Stefanie Jegelka
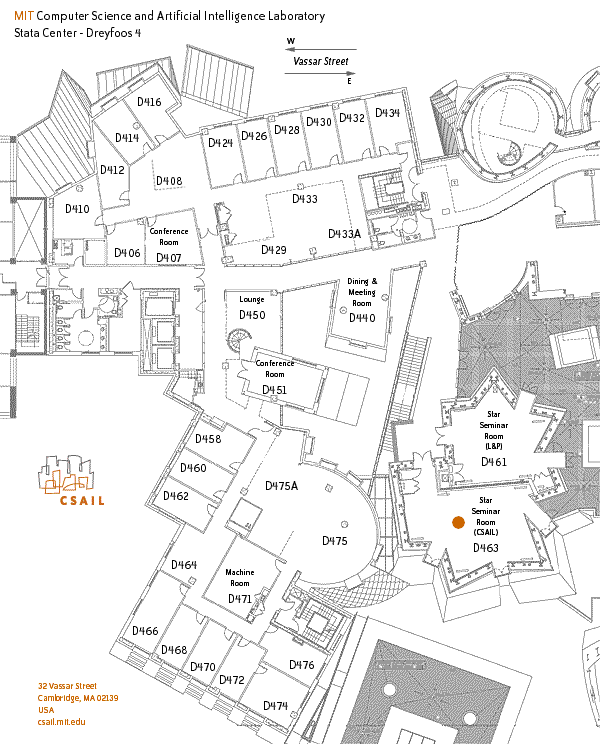{kind=link}
Abstract: When training large-scale deep neural networks for pattern recognition, hundreds of hours on clusters of GPUs are required to achieve state-of-the-art performance. Improved optimization algorithms could potentially enable faster industrial prototyping and make training contemporary models more accessible.
In this talk, I will attempt to distill the key difficulties in optimizing large, deep neural networks for pattern recognition. In particular, I will emphasize that many of the popularized notions of what make these problems “hard” are not true impediments at all. I will show that it is not only easy to globally optimize neural networks, but that such global optimization remains easy when fitting completely random data.
I will argue instead that the source of difficulty in deep learning is a lack of understanding of generalization. I will provide empirical evidence of high-dimensional function classes that are able to achieve state-of-the-art performance on several benchmarks without any obvious forms of regularization or capacity control. These findings reveal that traditional learning theory fails to explain why large neural networks generalize. I will close by discussing possible mechanisms to explain generalization in such large models, appealing to insights from linear predictors.
Bio: Benjamin Recht is an Associate Professor in the Department of Electrical Engineering and Computer Sciences at the University of California, Berkeley. Ben’s research focuses on scalable computational tools for large-scale data analysis, statistical signal processing, and machine learning. He is the recipient of a Presidential Early Career Awards for Scientists and Engineers, an Alfred P. Sloan Research Fellowship, the 2012 SIAM/MOS Lagrange Prize in Continuous Optimization, the 2014 Jamon Prize, and the 2015 William O. Baker Award for Initiatives in Research.
In this talk, I will attempt to distill the key difficulties in optimizing large, deep neural networks for pattern recognition. In particular, I will emphasize that many of the popularized notions of what make these problems “hard” are not true impediments at all. I will show that it is not only easy to globally optimize neural networks, but that such global optimization remains easy when fitting completely random data.
I will argue instead that the source of difficulty in deep learning is a lack of understanding of generalization. I will provide empirical evidence of high-dimensional function classes that are able to achieve state-of-the-art performance on several benchmarks without any obvious forms of regularization or capacity control. These findings reveal that traditional learning theory fails to explain why large neural networks generalize. I will close by discussing possible mechanisms to explain generalization in such large models, appealing to insights from linear predictors.
Bio: Benjamin Recht is an Associate Professor in the Department of Electrical Engineering and Computer Sciences at the University of California, Berkeley. Ben’s research focuses on scalable computational tools for large-scale data analysis, statistical signal processing, and machine learning. He is the recipient of a Presidential Early Career Awards for Scientists and Engineers, an Alfred P. Sloan Research Fellowship, the 2012 SIAM/MOS Lagrange Prize in Continuous Optimization, the 2014 Jamon Prize, and the 2015 William O. Baker Award for Initiatives in Research.