Generative AI systems like large language models rely heavily on deep learning - and, in particular, transformers. Transformers make use of an “attention mechanism” for modeling interactions among inputs, which essentially involves doing nonlinear pairwise comparison between inputs and assigning different weights to tokens in a sequence, enabling a prioritization of some over others. The empirical effectiveness of this attention mechanism has led some in the community to claim that attention is “all you need” (the title of the original 2017 Google paper that introduced transformers).
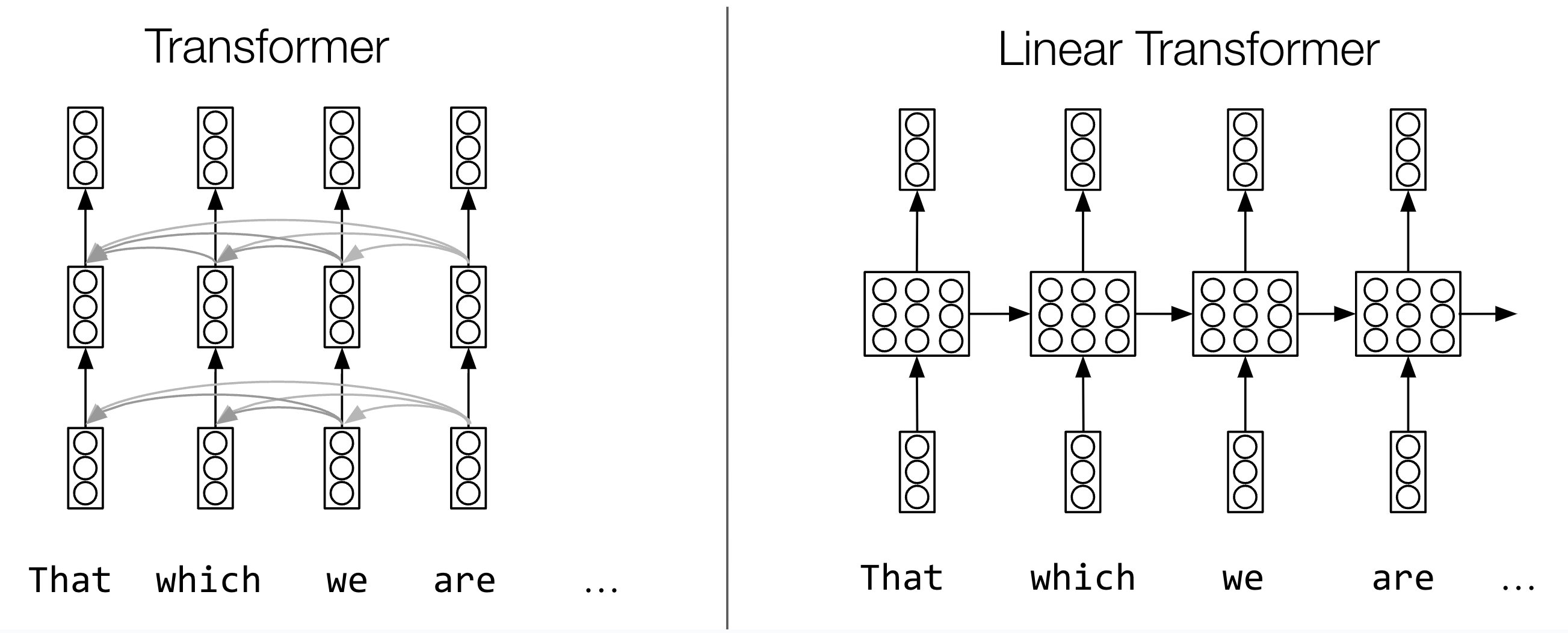
If you ask MIT assistant professor Yoon Kim, though, one limit for traditional transformers is that they can be inefficient: for a sequence of length L, you need to do work at the level of L squared. This makes it difficult to scale transformers to longer sequences, which is important for applications such as question-answering over multiple books and documents, imbuing LLM agents with long-term memory, and modeling other modalities such as video.
As a result, researchers have recently begun experimenting with so-called “linear transformers,” which involves removing the nonlinearity in the pairwise comparison mechanism in ordinary attention, making it linear. Kim says that this allows you to essentially restructure the computations of the linear transformer such that it’s a recurrent neural network, a classic model that computer scientists have used for 50 years for more efficient sequence processing.
However, linear transformers have their own downsides; they use a simple mechanism to update their recurrently-updated hidden states known as “memory,” which makes it difficult for them to tackle certain tasks such as long-range retrieval. In 2021 a research team led by machine learning pioneer Jürgen Schmidhuber made key progress on this challenge with a linear transformer that drew on the classic concept known as “the delta rule,” which operationalizes a key-value update mechanism in vector space, thus allowing it to outperform ordinary linear transformers.
But despite the improvements in performance, the more-involved delta rule update mechanism made it difficult to train such “DeltaNet” variants of linear transformers at scale: the algorithm given in the original paper was unable to leverage the parallel processing capabilities of modern hardware such as GPUs. In a paper out this past month, Kim’s group at the MIT Computer Science and Artificial Intelligence Laboratory (CSAIL) proposed a novel parallel algorithm for efficiently training DeltaNet transformers that allowed it to be scaled to modern language-model settings.
The CSAIL team demonstrated encouraging results in both synthetic experiments and real-world tasks in comparison to existing models. They looked at tasks that included language modeling, downstream natural language processing tasks, and targeted “associative recall” (a process where an associative memory, upon receiving a query, retrieves the associated value). In some cases the team’s models worked upwards of 30 times faster than the ones presented by Schmidhuber’s team in 2021.
Lead author Songlin Yang worked with Kim and colleagues to reparameterize DeltaNet as a matrix-valued recurrent neural network (RNN). They then borrowed from a nearly 40-year-old paper on “householder matrices,” a specific type of orthogonal matrix with properties that make them useful for linear algebra. These matrices allowed Kim’s team to create a memory-efficient representation that enabled better parallelization for modern hardware like graphic processing units (GPUs).
With all said, even with the delta rule linear transformers can still struggle with certain phenomena, which are better handled by the classic attention mechanism. Because of this, the researchers also explored “hybrid models” combining DeltaNet layers with attention mechanisms, which led to surprisingly robust performance improvements that, in some cases, even surpassed traditional transformers.
“This work provides a significant algorithmic improvement for training linear transformers with the delta rule, making them more practical for large-scale language modeling,” says Kim. “The hybrid model approach also shows the potential of combining linear-time models with traditional attention mechanisms for optimal performance.”
A PhD student at CSAIL, Yang co-authored the paper with Kim, former CSAIL postdoc Bailin Wang, PhD student Yu Zhang of Soochow University, and staff research scientist Yikang Shen of the MIT-IBM Watson AI Lab. They will be presenting the paper later this month at the Conference and Workshop on Neural Information Processing Systems (NeurIPS).



