When we hear a voice on the radio or the phone, we often build a mental model for the way that person looks. Is that sort of intuition something that computers can develop too?
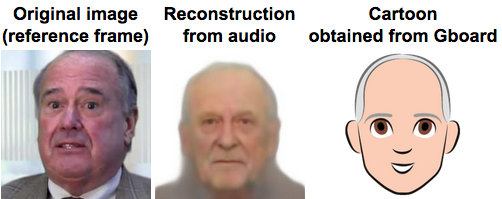
A team led by researchers from MIT’s Computer Science and Artificial Intelligence Lab (CSAIL) have recently shown that it can: they’ve created a new system that can produce a predicted image of someone’s face from hearing them talk for only five seconds.






Trained on millions of YouTube clips featuring over 100,000 different speakers, Speech2Face listens to audio of speech and compares it to other audio it’s heard. It can then create an image based on the facial characteristics most common to similar audio clips. The system was found to predict gender with ___ percent accuracy, age with , ___ percent accuracy, and race with ____ percent accuracy.
On top of that, the researchers even found correlations between speech and jaw shape - suggesting that Speech2Face could help scientists glean insights into the physiological connections between facial structure and speech. The team also combined Speech2Face with Google’s personalized emoji app to create “Speech2Cartoon,” which can turn the predicted face from live-action to cartoon.