{kind=link}
Add to Calendar
2024-04-23 10:30:00
2024-04-23 11:30:00
America/New_York
Thesis Defense: Learning the language of biomolecular interactions
Proteins are the primary functional unit of the cell, and their interactions drive cellular function. Interactions between proteins are responsible for a wide variety of functions raning from catalytic activity to cellular transport and signaling, and interactions between small molecules and proteins are the foundation of many therapeutics. However, the experimental determination of these interactions is expensive and relatively slow, limiting the ability to model interactions at genome scale. It is therefore critical to develop computational approaches for modeling these interactions. Unsupervised language models trained on amino acid sequences, namely protein language models, learn patterns in sequence evolution that encode protein structure and function. These protein language models are thus a powerful tool for extracting features of proteins, enabling the adoption of lightweight downstream models. Here, we present novel machine learning techniques for adapting protein language modeling to the prediction of protein interactions at scale, enabling de novo interaction network inference and large-scale drug compound screening. We show that these methods achieve state-of-the-art performance, and allow us to discover new biology and therapeutic candidates. In addition, we introduce methods for efficient training and adaptation of these models, and outline several applications which take advantage of the scale enabled by lightweight models. As a whole, this thesis demonstrates how computational advances in language modeling and the massive growth of data brought about by the sequencing revolution can be leveraged to tackle the genotype-to-phenotype challenge in biology, and lays the groundwork for more widespread adoption of these techniques for proteomic modeling.
32-G882
Events
April 23, 2024
{kind=link}
Add to Calendar
2024-04-23 11:00:00
2024-04-23 13:00:00
America/New_York
Thesis defense - Automated interpretation of machine learning models
As machine learning (ML) models are increasingly deployed in production, there’sa pressing need to ensure their reliability through auditing, debugging, and testing.Interpretability, the subfield that studies how ML models make decisions, aspiresto meet this need but traditionally relies on human-led experimentation or is basedon human priors about what the model has learned. In this thesis, I propose thatinterpretability should evolve alongside ML by adopting automated techniques thatuse ML models to interpret ML models. This shift towards automation allows formore comprehensive analyses of ML models without requiring human scrutiny atevery step, and the effectiveness of these methods should improve as the ML mod-els themselves become more sophisticated. I present three examples of automatedinterpretability approaches: using a captioning model to label features of other mod-els, manipulating a ML model’s internal representations to predict and correct er-rors, and identifying simple internal circuits through approximating the ML modelitself. These examples lay the groundwork for future efforts in automating ML modelinterpretation.
32-G449
Add to Calendar
2024-04-23 12:00:00
2024-04-23 13:00:00
America/New_York
Visual Computing Seminar | Tim Brooks - Sora: Video Generation Models as World Simulators
Virtual session of MIT Visual Computing Seminar, Spring 2024 featuring invited speaker (remote) Tim Brooks from OpenAI.The format is ~25 min of talk followed by Q&A. Considering the potential capacity of the talk, we use slido for live Q&A and answer top questions from the upvote queue. [live Q&A link] https://tinyurl.com/TimBrooksMITPlease DO NOT record this talk by any means. Thanks for your understanding. TitleSora: Video Generation Models as World SimulatorsAbstractWe explore large-scale training of generative models on video data. Specifically, we train text-conditional diffusion models jointly on videos and images of variable durations, resolutions and aspect ratios. We leverage a transformer architecture that operates on spacetime patches of video and image latent codes. Our largest model, Sora, is capable of generating a minute of high fidelity video. Our results suggest that scaling video generation models is a promising path towards building general purpose simulators of the physical world.Bio Tim Brooks is a research scientist at OpenAI where he co-leads Sora, their video generation model. His research investigates large-scale generative models that simulate the physical world. Tim received a PhD at Berkeley AI Research advised by Alyosha Efros, where he invented InstructPix2Pix. He previously worked on AI that powers the Pixel phone's camera at Google and on video generation models at NVIDIA.
https://mit.zoom.us/j/95167636032?pwd=U0dyaEx1a3A3QkZrbmIvMkcvUFkyUT09 (password: mitvc)
Cindy Hsin-Liu Kao - Designing Hybrid Skins
Cornell University
Add to Calendar
2024-04-23 16:00:00
2024-04-23 17:00:00
America/New_York
Cindy Hsin-Liu Kao - Designing Hybrid Skins
Abstract:Hybrid Skins are an emerging form of conformable interface situated at all scales of the human experience. These conformable interfaces are hybrid in their integration of technological function with social and cultural perspectives, blending historical craft with miniaturized robotics, machines, and materials in their development. The resulting skins also serve social, cultural, and technological purposes while supporting the construction of individual identities. This seminar examines recent work from the Hybrid Body Lab in designing Hybrid Skins through under-explored approaches of textile robotics, bio-fluid sensing, modular flexible electronics, and sustainable materials exploration. With their seamless and conformable form factor, Hybrid Skins afford unprecedented intimacy to the human experience and an opportunity for us to carefully rethink and redesign how our relationship with technology can, should (or should not) be. By blending engineering, design, and committed engagement with diverse communities, Kao and her lab’s research aims to foster inclusive design for future wearable technology that can celebrate (instead of constrict) the diversity of the human experience. Bio:Cindy Hsin-Liu Kao is an assistant professor at Cornell University. She directs the Hybrid Body Lab, which focuses on integrating cultural and social perspectives into the design of on-body interfaces. Through her research, she aims to foster inclusive designs for soft wearable technologies, like smart tattoos and textiles and develops novel digital fabrication methods. Kao, honored with a National Science Foundation CAREER Award, has received accolades in major ACM Human-Computer Interaction venues and media attention from Forbes, CNN, WIRED, and VOGUE. Her work has been showcased internationally, including at the Pompidou Centre in Paris and New York Fashion Week, earning multiple design awards. Kao holds a Ph.D. from MIT Media Lab.This talk will also be streamed over Zoom: https://mit.zoom.us/j/99183558682.
Star (D463)
On some Recent Dynamic Graph Algorithms
Yang Liu
IAS
Add to Calendar
2024-04-23 16:15:00
2024-04-23 17:15:00
America/New_York
On some Recent Dynamic Graph Algorithms
Abstract: We discuss some recent algorithms for problems in dynamic graphs undergoing edge insertions and deletions. In the first part of the talk, we will discuss connections between the approximate bipartite matching problem in fully dynamic graphs, and versions of the online matrix-vector multiplication conjecture. These connections will lead to faster algorithms in online and offline settings, as well as some conditional lower bounds.In the second part of the talk, we will briefly discuss how interior point methods can be used to design algorithms for partially dynamic graphs: those undergoing only edge insertions (incremental) or only edge deletions (decremental). This leads to almost-optimal algorithms for problems including incremental cycle detection, and decremental s-t distance.
32-G882
April 24, 2024
Add to Calendar
2024-04-24 11:00:00
2024-04-24 12:00:00
America/New_York
Unblocking CPU Performance Bottlenecks for Data Center Workloads
Abstract:Modern complex data center applications exhibit unique characteristicssuch as extensive data and instruction footprints, complex controlflow, and hard-to-predict branches that are not adequately served byexisting microprocessor architectures. In particular, these workloadsexceed the capabilities of microprocessor structures such as theinstruction cache, BTB, branch predictor, and data caches, causingsignificant degradation of performance and energy efficiency.In my talk, I will provide a characterization of data centerapplications, highlighting the importance of addressing frontend andbackend performance issues. I will then introduce new techniques toaddress these challenges by improving the branch predictor, datacache, and instruction scheduler. I will make the case forprofile-guided optimizations that amortize overheads across the fleet,which have been successfully deployed at Google and Intel, servingmillions of users daily.Bio:Heiner Litz is an Associate Professor at UC Santa Cruz, a visitingProfessor at MIT, and a consulting CPU architect at ARM. His researchfocuses on improving the performance, cost, and efficiency of datacenter systems. Heiner is the recipient of the NSF CAREER award,Intel's Outstanding Researcher award, a MICRO Best Paper award, twoIEEE MICRO Top Pick awards, and multiple Google Faculty Awards. Beforejoining UCSC, Heiner Litz was a researcher at Google and apostdoctoral research fellow at Stanford University with Prof.Christos Kozyrakis and David Cheriton. He received his Diplom andPh.D. from the University of Mannheim, Germany, advised by Prof.Bruening.Headshot:https://people.ucsc.edu/~hlitz/hlitz.jpegweb:https://people.ucsc.edu/~hlitz/
32-G882 Hewlett Room
{kind=link}
Add to Calendar
2024-04-24 16:00:00
2024-04-24 17:00:00
America/New_York
Lipschitz Continuous Graph Algorithms via Proximal Gradient Analysis
Abstract: We study the class of Lipschitz continuous graph algorithms as introduced in the recent work of Kumabe and Yoshida [FOCS'23]. The Lipschitz constant of an algorithm, intuitively, bounds the ratio of the changes in its output over the perturbations of its input. Our approach consists of three main steps. First, we consider a natural convex relaxation of the underlying graph problem with the addition of a smooth and strongly convex regularizer. Then, we give upper bounds on the ell-1 distance between the optimal solutions of the convex programs, under small perturbations of the weights, via a stability analysis of the trajectory of the proximal gradient method. Finally, we present new problem-specific rounding techniques to obtain integral solutions to several graph problems that approximately maintain the stability guarantees of the fractional solutions. We apply our framework to a number of problems including minimum s-t cut, multiway cut, densest subgraph, maximum b-matching, and packing integer programs. Finally, we show the tightness of our results for certain problems by establishing matching lower bounds.
32-G575
April 25, 2024
Thesis Defense: Symbolic-numeric programming in scientific computing
Shashi Gowda
MIT
Add to Calendar
2024-04-25 10:00:00
2024-04-25 12:00:00
America/New_York
Thesis Defense: Symbolic-numeric programming in scientific computing
32-G882
THESIS DEFENSE: Using Principles from Cognitive Science to Train and Analyze Language-Related Neural Networks
Mycal Tucker
CSAIL
{kind=link}
Add to Calendar
2024-04-25 11:00:00
2024-04-25 12:00:00
America/New_York
THESIS DEFENSE: Using Principles from Cognitive Science to Train and Analyze Language-Related Neural Networks
Committee: Prof. Julie Shah, H.N. Slater Professor of Aeronautics and Astronautics, MIT (Chair) Prof. Roger Levy, Professor of Brain & Cognitive Sciences, MIT Dr. Been Kim, Senior Research Staff Scientist, Google DeepMind Dr. Ellie Pavlick, Manning Assistant Professor of Computer Science and Assistant Professor of Linguistics, Brown University Prof. Jacob Andreas, Associate Professor of Electrical Engineering and Computer Science, MIT (Reader) Prof. Ted Gibson, Professor of Brain & Cognitive Sciences, MIT (Reader)Abstract:Natural language, while central to human experience, is not uniquely the domain of humans. AI systems, typically neural networks, exhibit startling language processing capabilities from generating plausible text to modeling simplified language evolution. To what extent are such AI models learning language in a "human-like'' way?Defining "human-like'' generally may be an impossible problem, but narrower definitions of aspects of human-like language processing, borrowed from cognitive science literature, afford metrics for evaluating AI models. In this thesis, I borrow two theories about human language processing for such analysis. First, human naming systems (e.g., a language's words for colors such as "red" or "blue") appear near-optimal in an information-theoretic sense of compressing meaning into a small number of words; I ask how one might train AI systems that behave similarly. Second, people understand and produce language according to hierarchical representations of structure; I study whether large language models use similar representations in predicting text. Thus, in this thesis, I show how to train and analyze neural networks according to cognitive theories of human language processing. In my first branch of work, I introduce a method for neural network agents to communicate according to cognitively-motivated pressures for utility, informativeness, and complexity. Utility represents a measure of task success and induces task-specific communication; informativeness is a task-agnostic measure of how well listeners understand speakers and leads to generalizable communication; complexity captures how many bits are allocated for communication and can lead to simpler communication systems. All three terms are important for human-like communication. In experiments, training artificial agents according to different tradeoffs between these properties led them to learn different naming systems that closely aligned with existing natural languages.In my second branch of work, rather than training neural agents from scratch, I probe pre-trained language models and found that some use representations of syntax in making predictions. Humans use hierarchical representations of sentence structure in understanding and producing language, but it is unclear if large language models, trained on simple tasks like next-word-prediction, should learn similar representations. I introduce a causal probing method that sheds light on this topic. By creating counterfactual representations of syntactically ambiguous sentences, I measured how model predictions changed for different structural interpretations of the same sentence. For example, I recorded model predictions to ambiguous inputs like "The girl saw the boy with the telescope. Who had the telescope?" with different syntactic structures. For some (but not all) models, I found that models use representations of syntax (e.g., change their answers to the previous question). Thus, I offer novel insight into pre-trained models and a new method for studying such models for other properties.The two halves of my thesis represent complementary approaches towards more human-like AI; training new models and analyzing pre-trained ones closes an AI development feedback loop. In this thesis, I explain my contributions to both parts of this loop and identify promising directions for future research.Zoom info:https://mit.zoom.us/j/97359606509?pwd=eUFTWUNGZXIvbHBCNklaRVFoRmRUdz09
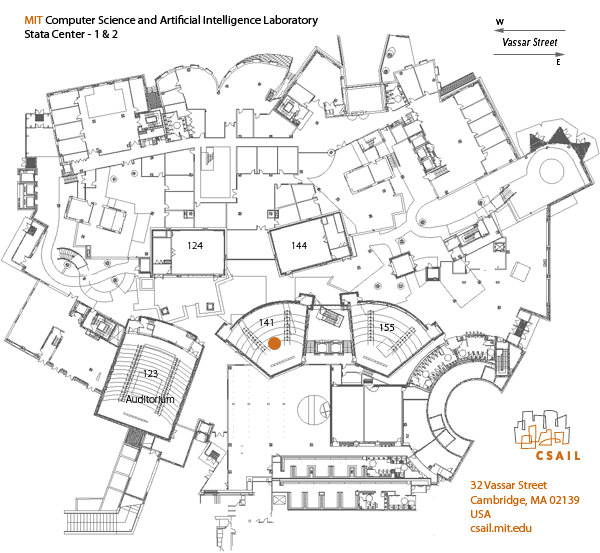
32-141
Constrained Pseudorandom Functions from Weaker Assumptions
Sacha Servan-Schreiber
MIT
Add to Calendar
2024-04-25 12:00:00
2024-04-25 13:00:00
America/New_York
Constrained Pseudorandom Functions from Weaker Assumptions
In this talk, I will present a framework for constructing Constrained Pseudorandom Functions (CPRFs) with inner-product constraint predicates, using ideas from subtractive secret sharing and related-key-attack (RKA) security. I will show three instantiations of the framework:1. an adaptively-secure construction in the random oracle model;2. a selectively-secure construction under the DDH assumption; and3. a selectively-secure construction under the assumption that one-way functions exist.All three instantiations are constraint-hiding and support inner-product predicates, leading to the first constructions of such expressive CPRFs under each corresponding assumption. Moreover, while the OWF-based construction is primarily of theoretical interest, the random oracle and DDH-based constructions are concretely efficient, which is shown via an implementation.
D-463 (Star)
Add to Calendar
2024-04-25 13:00:00
2024-04-25 14:15:00
America/New_York
Training Human-AI Teams
Committee: David Sontag (chair, supervisor), Arvind Satyanarayan, Elena Glassman, Eric HorvitzZoom: https://mit.zoom.us/j/91551860173 1-2pm ETAbstract: AI systems are augmenting humans' capabilities in settings such as healthcare and programming, forming human-AI teams. To enable more accurate and timely decisions, we need to optimize the performance of the human-AI team directly. In this thesis, we utilize a mathematical framing of the human-AI team and propose a set of methods that optimize the AI, the human, and the interface in which they communicate to enable better team performance. We first show how to provably train AI classifiers that complement humans and can defer the decision to humans when it is best to do so. However, in certain settings, AI cannot autonomously make decisions and thus only provides advice to humans. In that case, we build onboarding procedures that train humans to have an accurate mental model of the AI to enable appropriate reliance. Finally, we study how humans interact with large language models (LLMs) to write code. To understand current inefficiencies, we developed a taxonomy to categorize programmers' interactions with the LLM. Motivated by insight from the taxonomy, we leverage human feedback to know when to best display LLM suggestions. Bio: Hussein Mozannar is a PhD student at MIT in Social & Engineering Systems and Statistics, advised by David Sontag. His research focuses on augmenting humans with AI to help them complete tasks more efficiently. Specifically, he focuses on building AI models that complement human behavior and designing interaction schemes to facilitate human-AI interaction. Applications of his research include programming (GitHub Copilot) and healthcare (radiology and maternal health).
E18-304 - https://mit.zoom.us/j/91551860173
Cluster Analysis in High Dimensions: Robustness, Privacy, and Beyond
Shyam Narayanan
MIT CSAIL
Add to Calendar
2024-04-25 14:30:00
2024-04-25 15:30:00
America/New_York
Cluster Analysis in High Dimensions: Robustness, Privacy, and Beyond
Abstract: Cluster analysis is perhaps one of the most important subfields in high-dimensional data analysis. Traditionally, cluster analysis focuses on partitioning data into closely related groups, such as k-means clustering and learning mixture models. However, one sometimes overlooked part is understanding the location and shape of a single cluster: this encompasses problems such as mean estimation and covariance estimation. In this thesis, we study various classic problems relating to both identifying several clusters and learning a single cluster, for high-dimensional data. Additionally, we consider various socially motivated constraints such as robustness, privacy, and explainability, and how they affect the complexity of these problems.For the presentation, I will focus primarily on learning a single cluster, which connects deeply with natural parameter estimation and hypothesis testing questions. Moreover, I will focus on the relationship between robustness and differential privacy for these questions.Thesis Committee: Piotr Indyk (Advisor) - MITSam Hopkins - MITRonitt Rubinfeld - MITJelani Nelson - UC Berkeley
32-G449
Theory and Practice of Fair Food Allocation
Purdue University
{kind=link}
Add to Calendar
2024-04-25 16:00:00
2024-04-25 17:00:00
America/New_York
Theory and Practice of Fair Food Allocation
Abstract: Food rescue organizations worldwide are leading programs aimed at addressing food waste and food insecurity. Food Drop is such a program, run by the non-governmental organization Indy Hunger Network (IHN), in the state of Indiana, in the United States. Food Drop matches truck drivers with rejected truckloads of food --- food that would otherwise be discarded at a landfill --- to food banks. Matching decisions are currently made by the Food Assistance Programs Manager of IHN. In this talk, I will discuss a partnership with IHN with the goal of completely automating Food Drop. Motivated by this collaboration, I will present a series of theoretical models and results for the fair division of indivisible goods, with each model refining our understanding of the essence of IHN's problem. These results directly informed our choice of algorithm for matching drivers to food banks for the platform we built for IHN.
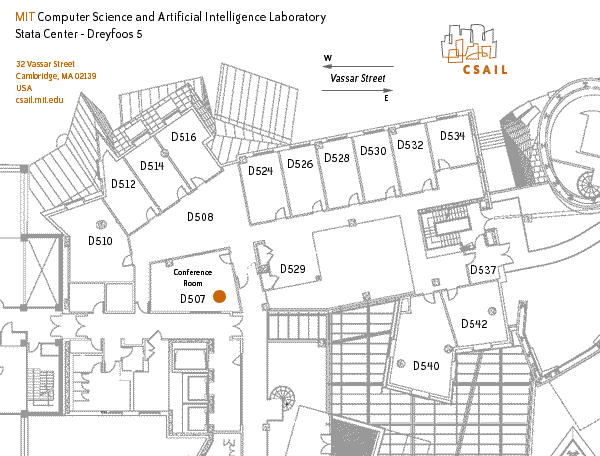
32-D507
ML-Tea: Ablation Based Counterfactuals
Zheng Dai
MIT CSAIL
Add to Calendar
2024-04-25 16:00:00
2024-04-25 16:30:00
America/New_York
ML-Tea: Ablation Based Counterfactuals
Abstract: The widespread adoption of diffusion models for creative uses such as image, video, and audio synthesis has raised serious questions surrounding the use of training data and its regulation. To arrive at a resolution, it is important to understand how such models are influenced by their training data. Due to the complexity involved in training and sampling from these models, the ultimate impact of the training data is challenging to characterize, confounding regulatory and scientific efforts. In this work we explore the idea of an Ablation Based Counterfactual, which allows us to compute counterfactual scenarios where training data is missing by ablating parts of a model, circumventing the need to retrain. This enables important downstream tasks such as data attribution, and brings us closer to understanding the influence of training data on these models.
32-370
April 26, 2024
Thesis Defense: Advancing Dexterous Manipulation via Machine Learning
Tao Chen
https://taochenshh.github.io/
{kind=link}
Add to Calendar
2024-04-26 13:00:00
2024-04-26 14:00:00
America/New_York
Thesis Defense: Advancing Dexterous Manipulation via Machine Learning
Abstract: Robots are becoming better at navigating and moving around, but they still struggle with using tools, which severely limits their usefulness for household tasks. Using tools requires dexterously manipulating everyday objects like hammers, scissors, knives, screwdrivers, etc. While simple for humans, manipulating everyday objects remains a long-standing challenge that requires breakthroughs in robotic hardware, sensing, perception, and control algorithms. This talk introduces machine learning techniques that substantially improve the state-of-the-art performance of dexterous manipulation controllers. It focuses specifically on in-hand object reorientation tasks. Previous works on this problem had limitations like using expensive sensors or hands, only working for a few objects, requiring the hand to face upward, slow object motion, etc. This talk discusses how we can go a step further by enabling a low-cost robot hand to dynamically reorient diverse objects in mid-air with the hand facing downward using an inexpensive depth camera. Bio: Tao Chen is a Ph.D. student advised by Prof. Pulkit Agrawal in Improbable AI lab at MIT CSAIL. His research focuses on robot learning, in particular, dexterous manipulation in robotics. He has received the Best Paper Award at the top robot learning conference, CoRL 2021, and has also published in the Science Robotics journal. Thesis committee: Pulkit Agrawal, Daniela Rus, Russ Tedrake
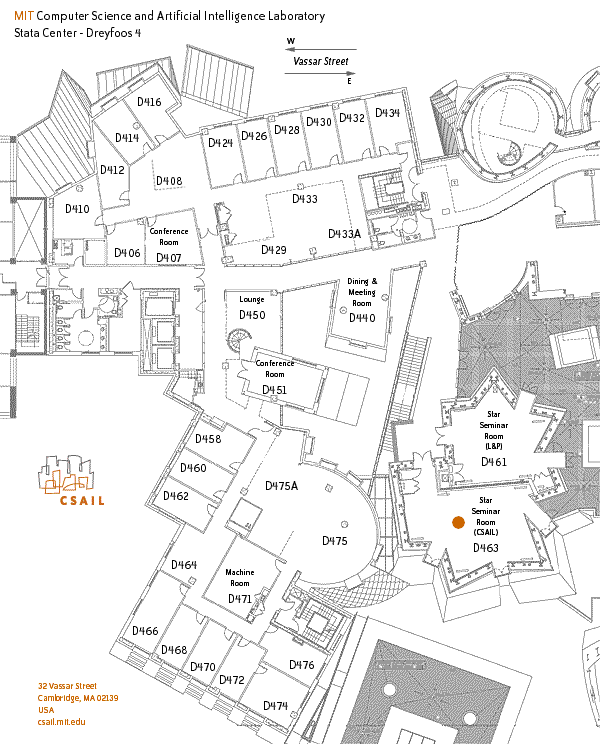
32-D463
April 29, 2024
Add to Calendar
2024-04-29 13:00:00
2024-04-29 14:00:00
America/New_York
ML-enabled Genetic Analysis of High-Content Phenotypes
Abstract: In my talk, I will discuss new machine learning (ML) approaches for human genetics. First, I will present ML-enhanced genetic analysis of histological traits, where we leverage a novel semantic autoencoder to compress histological images into trait embeddings for GWAS. In an application to multiple tissues from the GTEx dataset, we discover 4 genome-wide significant loci associated with histological changes, which we can visualise and interpret for each of the discovered variants thanks to our decoder.Second, I will introduce a new method combining machine learning and genetic causal inference for risk predictions. A key advantage of this method is that it doesn't require longitudinal data. This allows for risk prediction of late-onset diseases in large biobanks, where follow-up cases are often limited.Overall, these contributions demonstrate the transformative power of ML in human genetics. Our approaches enable more nuanced analyses of high-dimensional traits and facilitate biomarker discovery.Bio: Francesco Paolo Casale studied physics at the University of Naples Federico II, Italy. He received his PhD in statistical genetics at the University of Cambridge and the European Bioinformatics Institute in 2016, where he developed new computational methods for genetic association studies and contributed to landmark international projects such as the last phase of the 1000 Genomes Project and the Blueprint initiative. He conducted his postdoctoral studies at the Microsoft Research New England lab in Boston, working on deep generative models for imaging genetics and automated machine learning. In 2019, he joined insitro, a drug discovery and development company located in the bay area. There, he led the statistical genetics team, working at the intersection of human genetics, machine learning and functional genomics to enable target identification and characterization. Since January 2022, he is a Principal Investigator in Machine Learning in Biomedicine at the Helmholtz Munich Institute of AI for Health.
D507
April 30, 2024
Machine Learning Approaches for Healthcare Discovery, Delivery, and Equity
Yuzhe Yang
MIT-CSAIL
Add to Calendar
2024-04-30 10:00:00
2024-04-30 11:00:00
America/New_York
Machine Learning Approaches for Healthcare Discovery, Delivery, and Equity
Abstract: Today's clinical systems frequently exhibit delayed diagnoses, sporadic patient visits, and unequal access to care. Can we identify chronic diseases earlier, potentially before they manifest clinically? Furthermore, can we bring comprehensive medical assessments into patient’s own homes to ensure accessible care for all? In this talk, I will present machine learning approaches to bridge the persistent gaps in healthcare discovery, delivery, and equity. I will first introduce an AI-powered digital biomarker that detects Parkinson’s disease multiple years before clinical diagnosis, using just nocturnal breathing signals. I will then discuss a simple self-supervised framework for contactless measurement of human vital signs using smartphones. Finally, I will discuss principled methods to achieve equitable healthcare decision-making systems across diverse subpopulations and distribution shifts for real-world deployment. Committee Members: Dina Katabi (advisor, MIT), Marzyeh Ghassemi (MIT), Daniel McDuff (Google & University of Washington) Bio: Yuzhe Yang is a Ph.D. candidate at MIT, advised by Dina Katabi. His research interests include machine learning and AI for human diseases, health and medicine. His research has been published in Nature Medicine, Science Translational Medicine, NeurIPS, ICML, and ICLR, and featured in media outlets such as WSJ, Forbes, and BBC. He is a recipient of the Rising Stars in Data Science, and PhD fellowships from MathWorks and Takeda.
32-D463 (Star). Will be hybrid and have a Zoom link, please contact (yuzhe@mit.edu) for the link
Privacy-Preserving ML with Fully Homomorphic Encryption
Jordan Frery and Benoit Chevallier-Mames
Zama
Add to Calendar
2024-04-30 14:00:00
2024-04-30 15:00:00
America/New_York
Privacy-Preserving ML with Fully Homomorphic Encryption
Abstract:In the rapidly evolving field of artificial intelligence, the commitment to data privacy and intellectual property protection during Machine Learning operations has become a foundational necessity for society and businesses handling sensitive data. This is especially critical in sectors such as healthcare and finance, where ensuring confidentiality and safeguarding proprietary information are not just ethical imperatives but essential business requirements.This presentation goes into the role of Fully Homomorphic Encryption (FHE), based on the open-source library Concrete ML, in advancing secure and privacy-preserving ML applications.We begin with an overview of Concrete ML, emphasizing how practical FHE for ML was made possible. This sets the stage for discussing how FHE is applied to ML inference, demonstrating its capability to perform secure inference on encrypted data across various models. After inference, we speak about another important FHE application, the FHE training and how encrypted data from multiple sources can be used for training without compromising individual user's privacy.FHE has lots of synergies with other technologies, in particular Federated Learning: we show how this integration strengthens privacy-preserving features of ML models during the full pipeline, training and inference.Finally, we address the application of FHE in generative AI and the development of Hybrid FHE models (which are the subject of our RSA 2024 presentation). This approach represents a strategic balance between intellectual property protection, user privacy and computational performance, offering solutions to the challenges of securing one of the most important AI applications of our times.BiosJordan Frery is a research scientist and engineer in machine learning at Zama. As a researcher, he published in different application domains such as fraud detection, author verification, and risk prediction. He holds a PhD in machine learning and has worked in the field for 8+ years, as a data and research scientist. His current work at Zama focuses on bridging the gap between machine learning and fully homomorphic encryption, with the goal of applying machine learning techniques to encrypted data.Benoit Chevallier-Mames is a security engineer and researcher serving as VP of Cloud & Machine Learning at Zama. He has spent 20+ years between cryptographic research and secure implementations in a wide range of domains such as side-channel security, provable security, whitebox cryptography, and fully homomorphic encryption. Prior to Zama, he securely implemented public-key algorithms on smartcards in Gemplus for seven years, worked for the French governmental ANSSI agency for one year, and then designed and developed whitebox implementations at Apple for 12 years. Benoit has co-written 15+ peer-reviewed papers and is the co-author of 50+ patents. He holds a PhD from Ecole Normale Superieure / Paris University and a master's degree from CentraleSupelec.
32-G882
May 02, 2024
Thesis Defense: Learning to Model Atoms Across Scales
Xiang Fu
MIT CSAIL
Add to Calendar
2024-05-02 13:30:00
2024-05-02 14:30:00
America/New_York
Thesis Defense: Learning to Model Atoms Across Scales
The understanding of atoms and how they interact forms the foundation of modern natural science, as well as material and drug discovery efforts. Computational chemistry methods such as density functional theory and molecular dynamics simulation can offer an unparalleled spatiotemporal resolution for observing microscopic mechanisms and predicting macroscopic phenomena. However, their computational cost limits the applicable domains and scales. This thesis presents machine learning methods for modeling atoms for tasks across different scales. First, we propose machine learning force fields that can decompose molecular interactions into fast and slow components, and then accelerate molecular simulations through multi-scale integration. Second, we propose an end-to-end workflow for learning time-integrated coarse-grained molecular dynamics using multi-scale graph neural networks. Third, we propose diffusion models for periodic material structures and their multi-scale extension to metal-organic frameworks. These machine-learning methods represent a new paradigm in high-throughput scientific discovery and molecular design.
Add to Calendar
2024-05-02 14:00:00
2024-05-02 16:00:00
America/New_York
Designing for Participation and Power in Data Collection and Analysis
Thesis committee: Arvind Satyanarayan, Daniel Jackson, Catherine D’Ignazio, J. Nathan MatiasAbstract:Technologies that mediate social participation are an increasingly important area for design, enabling people to create, share, and discuss information. While increased participation is generally considered empowering, it can also be a double-edged sword, as involuntary participation in systems can lead to disempowerment. In this dissertation, I apply the lens of participation and power to two problem domains: accessible data visualization and ethical data collection. First, existing approaches to accessible data visualization reinforce blind and low-vision (BLV) users' dependence on sighted assistance. In contrast, I design systems that empower BLV users to conduct self-guided data exploration and create non-visual representations without using visual idioms. Second, existing data ethics procedures are often designed to offer people more choices, but can serve to placate users and consolidate data collectors' power. I develop systems and frameworks that offer novel approaches to data protection by reframing people's non-compliance with data collection as a form of socio-technical design. Altogether, this work demonstrates how the lens of participation and power deepens our understanding of technology's social implications and inspires novel approaches to design.
32-G882
May 06, 2024
Thesis Defense: Towards Object-based SLAM
Yihao Zhang
MIT MechE
Add to Calendar
2024-05-06 10:00:00
2024-05-06 11:30:00
America/New_York
Thesis Defense: Towards Object-based SLAM
Abstract:Simultaneous localization and mapping (SLAM) is a fundamental capability for a robot to perceive its surrounding environment. The research area has developed for more than two decades from the original sparse landmark-based SLAM to dense SLAM, and now there is a demand for semantic understanding of the environment beyond pure geometric understanding. This thesis makes a number of contributions to help realize object-based SLAM, in which the map consists of a set of objects with their semantic categories recognized and their poses and shapes estimated. Such a map provides vital object-level semantic and geometric perception for applications such as augmented reality (AR), mixed reality (MR), mobile manipulation, and autonomous driving.In order to perform object-based SLAM, the sensor measurements have to undergo a series of processes. First, objects are semantically segmented in the sensor measurements. This step is typically done by a neural network. As robots are often required to bootstrap from some initial labeled datasets and adapt to different environments where labeled data are unavailable, it is important to enable semi-supervised learning to improve the robot performance with the unlabeled data collected by the robot itself. Second, after the objects are segmented, measurements for each object across different viewpoints have to be associated together for downstream processing. Lastly, the robot must be able to extract the object pose and shape information from the measurements without access to the detailed CAD models of the objects. This thesis studies these three aspects of object-based SLAM, namely semi-supervised learning of semantic segmentation in a robotics context, data association for object-based SLAM, and category-level object pose and shape estimation.For category-level object pose and shape estimation, we developed ShapeICP (ICP: iterative closest point), an algorithm that does not use pose-annotated data and generates meshes as the object shape representation. For data association, we developed DAF-SLAM (DAF: data association free) to estimate the associations in the back-end instead of relying on sensor-dependent front-end methods. For semi-supervised learning, we applied temporal semantic consistency inspired by the photometric consistency technique in the traditional SLAM methods. Each contribution is evaluated via experimental datasets, demonstrating improvements over previous techniques.Committee Members:John J. Leonard (Advisor), Department of Mechanical EngineeringFaez Ahmed, Department of Mechanical EngineeringNicholas Roy, Department of Aeronautics and Astronautics
32-G882 (https://mit.zoom.us/j/92202523862)
May 07, 2024
Quest | CBMM Seminar Series: Invariance and equivariance in brains and machines
Bruno Olshausen
UC Berkeley
Add to Calendar
2024-05-07 16:00:00
2024-05-07 17:30:00
America/New_York
Quest | CBMM Seminar Series: Invariance and equivariance in brains and machines
Abstract: The goal of building machines that can perceive and act in the world as humans and other animals do has been a focus of AI research efforts for over half a century. Over this same period, neuroscience has sought to achieve a mechanistic understanding of the brain processes underlying perception and action. It stands to reason that these parallel efforts could inform one another. However recent advances in deep learning and transformers have, for the most part, not translated into new neuroscientific insights; and other than deriving loose inspiration from neuroscience, AI has mostly pursued its own course which now deviates strongly from the brain. Here I propose an approach to building both invariant and equivariant representations in vision that is rooted in observations of animal behavior and informed by both neurobiological mechanisms (recurrence, dendritic nonlinearities, phase coding) and mathematical principles (group theory, residue numbers). What emerges from this approach is a neural circuit for factorization that can learn about shapes and their transformations from image data, and a model of the grid-cell system based on high-dimensional encodings of residue numbers. These models provide efficient solutions to long-studied problems that are well-suited for implementation in neuromorphic hardware or as a basis for forming hypotheses about visual cortex and entorhinal cortex.Bio: Professor Bruno Olshausen is a Professor in the Helen Wills Neuroscience Institute, the School of Optometry, and has a below-the-line affiliated appointment in EECS. He holds B.S. and M.S. degrees in Electrical Engineering from Stanford University, and a Ph.D. in Computation and Neural Systems from the California Institute of Technology. He did his postdoctoral work in the Department of Psychology at Cornell University and at the Center for Biological and Computational Learning at the Massachusetts Institute of Technology. From 1996-2005 he was on the faculty in the Center for Neuroscience at UC Davis, and in 2005 he moved to UC Berkeley. He also directs the Redwood Center for Theoretical Neuroscience, a multidisciplinary research group focusing on building mathematical and computational models of brain function (see http://redwood.berkeley.edu).Olshausen's research focuses on understanding the information processing strategies employed by the visual system for tasks such as object recognition and scene analysis. Computer scientists have long sought to emulate the abilities of the visual system in digital computers, but achieving performance anywhere close to that exhibited by biological vision systems has proven elusive. Dr. Olshausen's approach is based on studying the response properties of neurons in the brain and attempting to construct mathematical models that can describe what neurons are doing in terms of a functional theory of vision. The aim of this work is not only to advance our understanding of the brain but also to devise new algorithms for image analysis and recognition based on how brains work.
Singleton Auditorium (46-3002)
Parallel Derandomization for Chernoff-like Concentrations
Mohsen Ghaffari
CSAIL MIT
Add to Calendar
2024-05-07 16:15:00
2024-05-07 17:15:00
America/New_York
Parallel Derandomization for Chernoff-like Concentrations
Abstract: Randomized algorithms frequently use concentration results such as Chernoff and Hoeffding bounds. A longstanding challenge in parallel computing is to devise an efficient method to derandomize parallel algorithms that rely on such concentrations. Classic works of Motwani, Naor, and Naor [FOCS'89] and Berger and Rompel [FOCS'89] provide an elegant parallel derandomization method for these, via a binary search in a k-wise independent space, but with one major disadvanage: it blows up the computational work by a (large) polynomial. That is, the resulting deterministic parallel algorithm is far from work-efficiency and needs polynomial processors even to match the speed of single-processor computation. This talk overviews a duo of recent papers that provide the first nearly work-efficient parallel derandomization method for Chernoff-like concentrations.Based on joint work with Christoph Grunau and Vaclav Rozhon, which can be accessed via https://arxiv.org/abs/2311.13764 and https://arxiv.org/abs/2311.13771.
32-G882
May 10, 2024
Pseudorandom Error-Correcting Codes
Miranda Christ (Columbia University)
Add to Calendar
2024-05-10 10:30:00
2024-05-10 12:00:00
America/New_York
Pseudorandom Error-Correcting Codes
We construct pseudorandom error-correcting codes (or simply pseudorandom codes), which are error-correcting codes with the property that any polynomial number of codewords are pseudorandom to any computationally-bounded adversary. Efficient decoding of corrupted codewords is possible with the help of a decoding key.We build pseudorandom codes that are robust to substitution and deletion errors, where pseudorandomness rests on standard cryptographic assumptions. Specifically, pseudorandomness is based on either 2^{O(\sqrt{n})}-hardness of LPN, or polynomial hardness of LPN and the planted XOR problem at low density.As our primary application of pseudorandom codes, we present an undetectable watermarking scheme for outputs of language models that is robust to cropping and a constant rate of random substitutions and deletions. The watermark is undetectable in the sense that any number of samples of watermarked text are computationally indistinguishable from text output by the original model. This is the first undetectable watermarking scheme that can tolerate a constant rate of errors.Our second application is to steganography, where a secret message is hidden in innocent-looking content. We present a constant-rate stateless steganography scheme with robustness to a constant rate of substitutions. Ours is the first stateless steganography scheme with provable steganographic security and any robustness to errors.This is based on joint work with Sam Gunn: https://eprint.iacr.org/2024/235
32-G882 Hewlett Room
May 24, 2024
Dynamic Adaptive Optimization: Recovering from Hardware Errors and Software Crashes in a Distributed Virtual Machine
University of California, Santa Cruz
Add to Calendar
2024-05-24 14:00:00
2024-05-24 15:00:00
America/New_York
Dynamic Adaptive Optimization: Recovering from Hardware Errors and Software Crashes in a Distributed Virtual Machine
Abstract: TidalScale was a startup aquired by HPE in December 2022. TidalSale developed a software architecture called distributed virtual machines. Today's virtual machines in widespread use today allows multiple operating systems to share a server. TidalScale inverts this paradigm. A single virtual machine running on TidalScale runs a single operating system instance across a cluster of standard servers. This virtual machine sits between an operating system and a cluster of servers. It runs on premise or in the cloud. Because they are virtual, resources like processors and memory can migrate among nodes in the cluster. The virtual machine dynamically self-optimizes resource placement in real time under contol of a set of machine learning algorithms. Servers can automatically and dynamically be added and removed depending on fluctuationg workloads, allowing for dynamic hardware scalability, but also increasing reliability and resiliency. In this talk, we specifically show how these servers automatically, without any human intervention, recover from most hardware failures, and and provide excellent restart performance should OS failures occur.Bio: Ike Nassi is a consultant and an Adjunct Professor of Computer Science at UC Santa Cruz, a Founding Trustee at the Computer History Museum and an advisory board member of TTI/Vanguard. Ike was the founder of TidalScale, sold to HPE Dec. 2022. Previously, he was an Executive Vice President and Chief Scientist at SAP. Ike started or helped to start four companies: Encore Computer Corporation building hierarchical strongly coherent shared memory symmetric multiprocessors (1984); InfoGear Technology, which developed both Internet appliances (including the first iPhone) (1996); Firetide, an early wireless mesh networking company (2000), and TidalScale (2012). He was SVP for Software at Apple Computer and a Corporate Officer. He worked at Visual Technology, and Digital Equipment Corporation. In the past, Dr. Nassi was a Visiting Scholar at Stanford University, twice a Research Scientist at MIT, and a Visiting Scholar at University of California, Berkeley. He has served on the board of the Anita Borg Institute for Women and Technology, and the IEEE Computer Society Industry Advisory Board. He holds a PhD in Computer Science from Stony Brook University.He was awarded two certificates for Distinguished Service from the Department of Defense, one for his work on the design of the programming language Ada and one for his work on DARPA ISAT. He is a Life Fellow of IEEE and a Life member of ACM. He is named on over 35 patents.
32-G575
June 07, 2024
Add to Calendar
2024-06-07 9:00:00
2024-06-07 18:00:00
America/New_York
CSAIL + Imagination in Action Symposium 2024
The symposium will showcase the extraordinary and substantive contributions CSAIL research groups have made, and highlight the remarkable impacts of our work.
Kirsch Auditorium